
에게해 스터디원들과 함께하는 CS 간단 발표 및 독후감👻
[1일1로그 100일 완성 IT지식] 20번 '10억 개 전화번호에서 이름찾기: 이진검색'
지금은 사라져버린 두꺼운 전화번호부 책을 생각해봅시다~
그곳에서 '엄준식' 이라는 이름을 찾아보면!
우린 엄준식을 찾으려고 1페이지부터 찾지는 않을거다. 중간쯤 펴서 첫글자가 '엄' 보다 앞에있으면(ex. '신준식' 이라면) 적당히 뒤쪽을 찾아볼거고 '엄'보다 뒤에있으면(ex. '정준식' 이라면) 적당히 앞쪽을 찾아볼꺼다.
이 행동을 여러번 해서 결국 엄준식을 찾는게 이진 방법이다.

[1일1로그 100일 완성 IT지식] 21번 '검색을 쉽게 만드는 선택 정렬 vs 퀵 정렬'
하지만 현실은 녹록치 않은법.. 전화번호부처럼 모든 데이터가 이름 순으로 정렬되어 있지는 않다ㅠ
정렬은 크게 선택 정렬과 퀵 정렬이 있다.
선택 정렬
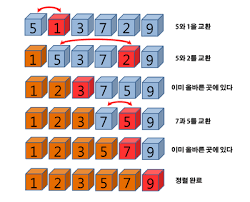
위 그림같이 데이터 하나하나 비교해 가장 작은수를 앞으로 보내주는 방법이다.
요 방법은 데이터의 갯수가 n개라고 할때 n(n+1)/2 번 반복해야 모든 데이터가 정렬된다.
따라서, 위 그림은 6(6+1)/2 => 21번의 반복후에 모든 데이터가 정렬이된다.
데이터의 수가 많아질 수록 반복행동이 엄청나게 많아지는 단점이 있다.
퀵 정렬
아래와 같이 처음에 소개한 이진정렬 느낌으로 정렬한다.

데이터 중 가운데수로 정렬할 데이터들을 2등분한다. 2등분 한 각각의 데이터들을 가운데수로 도 2등분한다.
이를 반복해 각각의 데이터가 0 or 1개가 될때까지 반복해 오름차순으로 만들어준다.
이는 데이터의 개수가 n개일때 nlogn (밑수가 2인 log) 번 반복하면 정렬이 완료된다.
아래 그림처럼 데이터의 개수가 커지면 선택 정렬(대충 n제곱)보다 압도적으로 적은 반복으로 정렬을 완료시킬 수 있다.

'CS 스터디' 카테고리의 다른 글
| [소프트웨어] 알고리즘은 이상, 프로그래밍은 현실 (0) | 2022.08.05 |
|---|---|
| [소프트웨어] 10개 도시를 최단거리로 여행하는 법 (0) | 2022.08.04 |
| [소프트웨어] 알고리즘과 초콜릿 케이크 레시피 (0) | 2022.08.02 |
| [하드웨어] 슈퍼컴퓨터부터 사물인터넷까지 (0) | 2022.08.01 |
| [하드웨어] 캐시가 뭔가요? (0) | 2022.07.30 |